黄河科技学院本科毕业设计 任务书
工 学部 大数据与计算机应用 科教中心 计算机科学与技术 专业
2018 级普本1/专升本1班 学号 学生 指导教师
毕业设计题目
基于实时音乐数据挖掘的个性化推荐系统设计与优化
毕业设计工作内容与基本要求(目标、任务、途径、方法,应掌握的原始资料(数据)、参考资料(文献)以及设计技术要求、注意事项等)
一、设计的目标和任务
- 第一部分:爬虫爬取音乐数据(网易云音乐网站),作为测试的数据集。
- 第二部分:离线推荐系统:python+机器学习离线推荐(基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度) ,必要时可以集成算法框架比如tensflow pytroch等,推荐结果通过pymysql写入mysql。同时当出现算法精准度低、计算速度慢时可以优化参数、算法逻辑、数据库索引等提升推荐算法的效率。
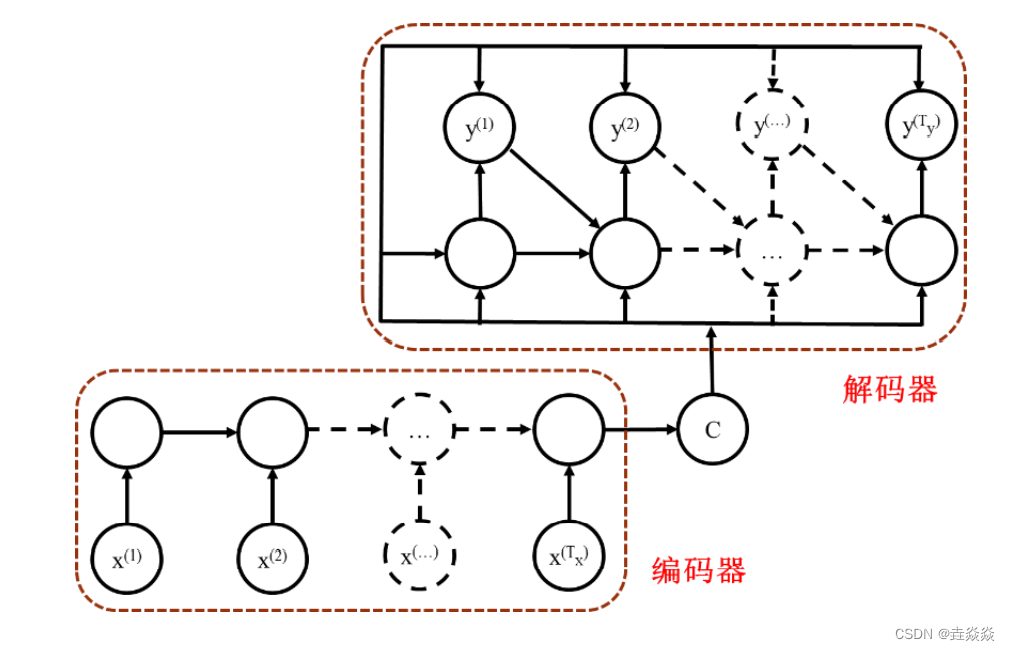
- 第三部分:在线应用系统: springboot进行在线推荐 vue.js构建推荐页面(含知识图谱)。
- 第四部分:使用Spark构建大屏统计。
二、设计途径和方法
- Selenium自动化Python爬虫工具采集网易云音乐、评论数据约1000万条存入.csv文件作为数据集;
- 使用pandas+numpy或MapReduce对数据进行数据清洗,生成最终的.csv文件并上传到hdfs;
- 使用hive数仓技术建表建库,导入.csv数据集;
- 离线分析采用hive_sql完成,实时分析利用Spark之Scala完成;
- 统计指标使用sqoop导入mysql数据库;
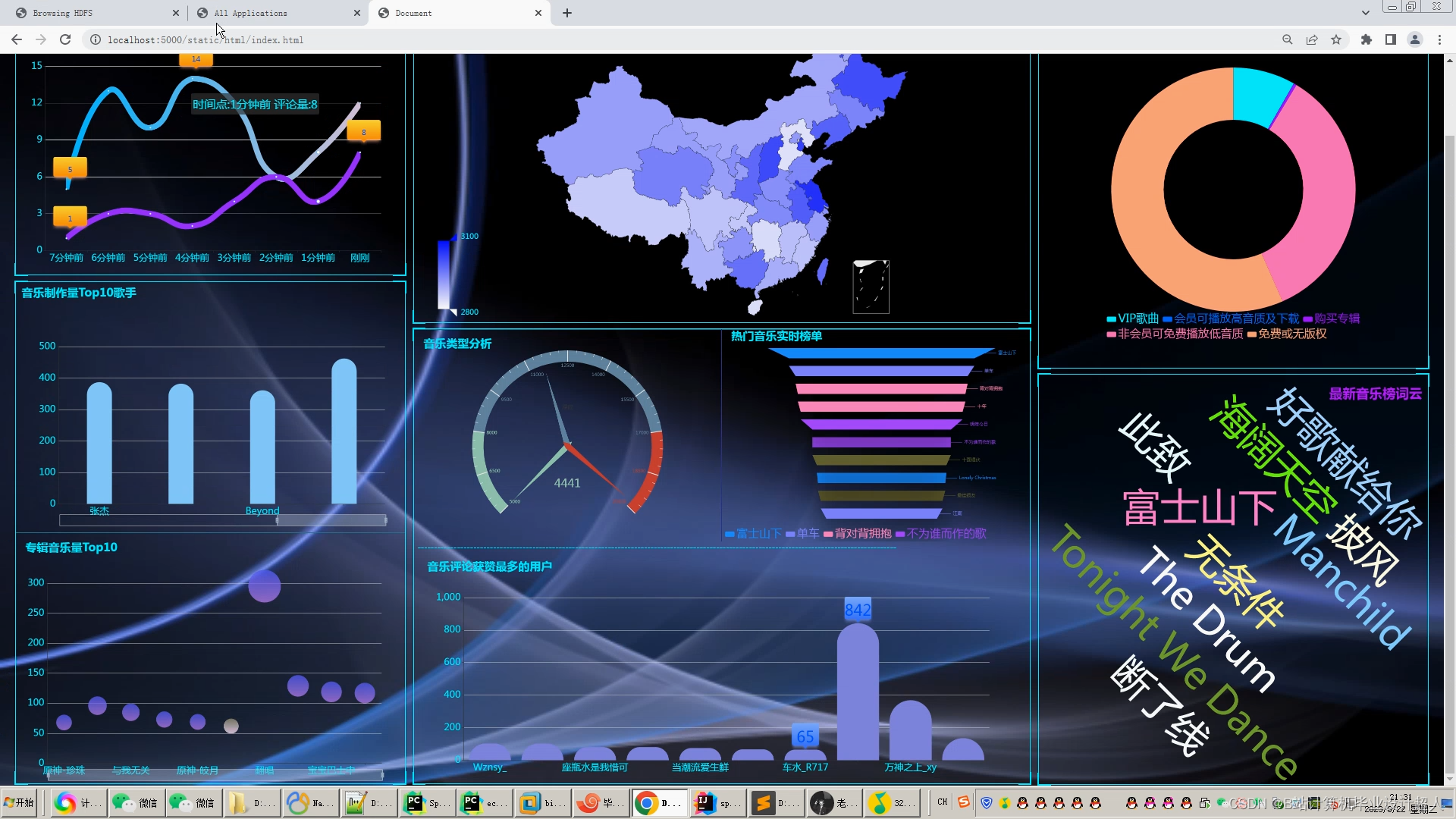
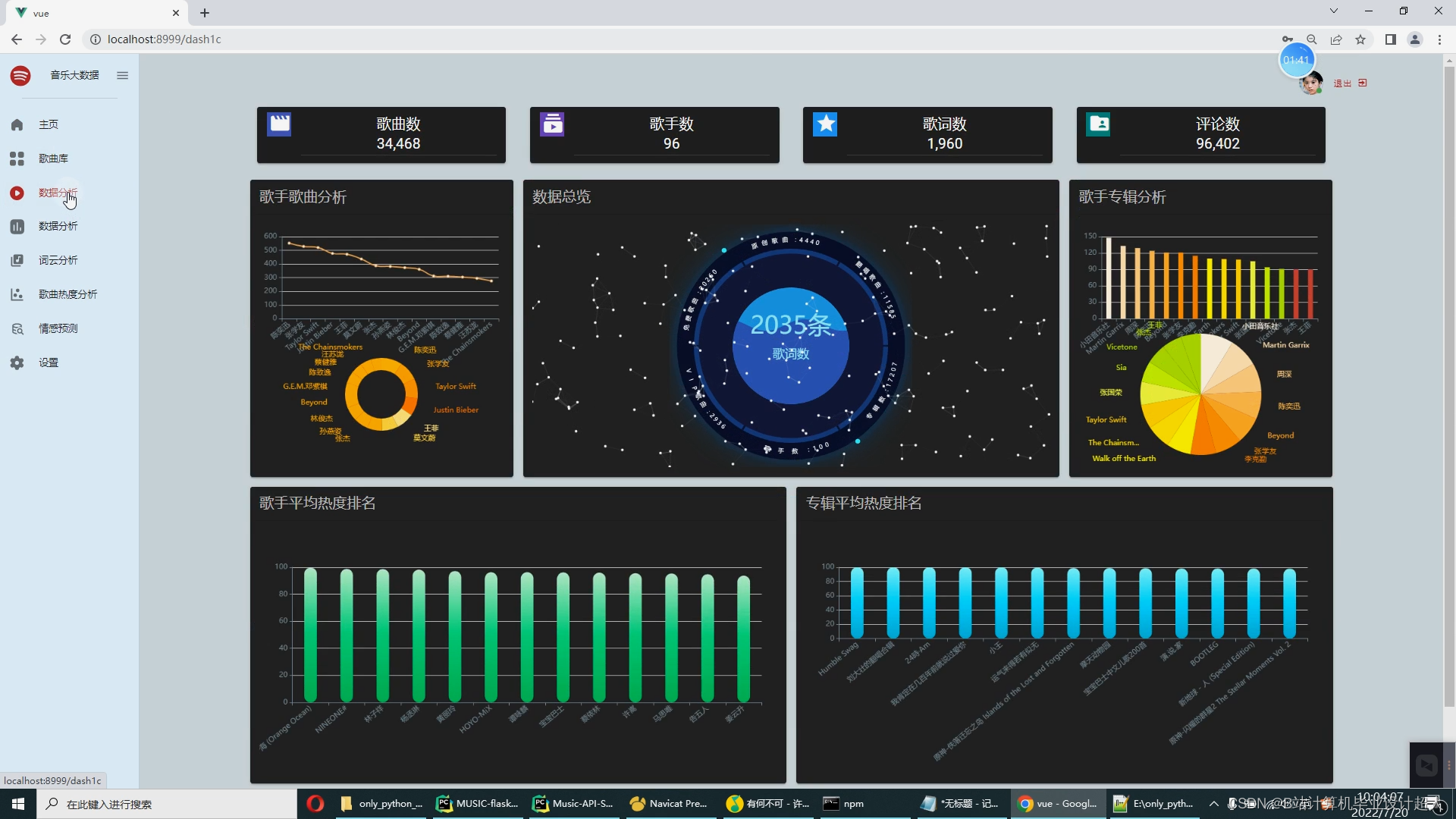
- 使用springboot+vue.js+echarts进行可视化大屏开发;
- 使用基于物品的协同过滤算法,相似度衡量方法:皮尔逊相似度等算法实现个性化音乐推荐并进行参数优化、算法二次开发升级;
- 使用卷积神经网络KNN、CNN实现音乐流量预测;
- 搭建springboot+vue.js前后端分离web系统进行个性化推荐界面、流量预测界面、知识图谱等实现;
三、应掌握的原始资料和技术
- 前端技术方案:登录vue官网,效仿案例Demo完成基本语法的入门,熟悉后积累本系统需要的开发组件,封装成.vue文件来回复用。学习vue.js前端框架,寻找符合本系统的框架,引入后完成页面开发。
- 后端技术方案:选用Springboot作为后端开发框架,相比SSM简洁高效,语法灵活,更适合小白新手快速入手,如Python开发中的Flask框架一样简单方便;
- 数据库技术方案:去CSDN寻找音乐推荐系统相关的建表经验,以多个系统建表的方案为依托,安装mysql,学习mysql语法,把数据库完整创建好;
- 爬虫技术方案:使用网易云代理站点完成数据爬取,包括音乐信息、评论、歌词等,主要运用Python爬虫技术,包括selenium、requests等;
- 推荐算法技术方案:充分研究协同过滤算法基于用户、基于物品两种实现,以及算法冷却问题,使用Python熟悉算法的调用过程,把调用代码集成到系统中,实现个性化音乐推荐.同时对算法参数、工作逻辑进行优化提升推荐效率;
(六)大数据技术方案:搭建hadoop、spark、hive大数据环境,进行数据可视化分析;
四、进度安排
第1周:查阅相关资料,完成文献综述。
第2周:结合课题要求,提交开题报告,并完成开题答辩。
第3~5周:进行系统分析、总体设计和详细设计。
第6~9周:实现系统编码、调试及软件测试。撰写毕业设计。
第10~12周:修改毕业设计至定稿,资格审查。
第13~14周:毕业设计答辩及资料归档。
五、参考文献
[1]LAWRENCERD, ALMASIGS, KOTLYARV, et al. Personalization of supermarket product recommendations[ R]. IBM Research Report,2020(7):173-181
[2]徐小伟. 基于信任的协同过滤推荐算法在电子商务推荐系统的应用研究. 东华大学. 2023
[3] 吴正洋. 个性化学习推荐研究. 华南师范大学期刊.2021
[4]李雪. 基于协同过滤的推荐系统研究. 吉林大学. 2020
[5]《数据库系统概论》[M],高等教育出版社. 2020
[6]马建红.JSP应用与开发技术.第三版.清华大学出版社.2022
[7] JavaEE架构设计与开发实践[M],方巍著:清华大学出版社.2022.1
[8] Spring Boot编程思想核心篇[M],小马哥著:电子工业出版社.2023.4
[9] Spring Boot开发实战M].吴胜著:清华大学出版社.2023.6
[10]Oleg Sukhoroslov. Building web-based services for practical exercises in parallel and distributed computing[J]. Journal of Parallel and Distributed Computing.2023.
六、注意事项
(1)对于开发过程中遇到的问题注重自己查阅资料寻找解决方案,同时,多和导师沟通交流解决。
(2)寻找同类系统进行对比学习和参考,提高开发效率。
毕业设计时间: 2022年 12 月 19 日至 2023年 5 月 13 日
计划答辩时间: 2023年 5 月 13 日
工作任务与工作量要求:原则上查阅文献资料不少于12篇,其中外文资料不少于2篇;文献综述不少于3000字;毕业论文或设计说明书不少于8000字(同时提交有关图纸和附件)。毕业设计(论文)撰写规范及有关要求,请查阅《黄河科技学院本科毕业设计(论文)指导手册》。
专业教研室审批意见:
审批人(签字):



核心算法代码分享如下:
# -*- codeing = utf-8 -*-
# Author: Tesla Tech
# XX: XXXX
# @Time: 2022/4/29 12:10
# @Author: Administrator
# @File: comment.py
# @Desc: 获取歌曲评论
import random
from time import sleep
import pandas as pd
from util import db, getLyric, getComment
def init():
print('初始化爬取任务表')
df = pd.read_sql("select songId, songName from tb_song where songId not in (select songId from tb_task)", con=db)
df.to_sql(name="tb_task", con=db, if_exists='append', index=False)
print('初始化完成,新增歌曲爬取任务:' + str(df.shape[0]))
def spider():
print('开始评论爬取...')
df = pd.read_sql("select songId from tb_task where status_comment='0' limit 1000", con=db)
# print(df.values.tolist())
# getComment('65766')
i = 0
for id in df.values.tolist():
i = i+1
print('index=',i,',songId=', id)
sleeptime = random.randint(10, 20)
sleep(sleeptime)
getComment(id[0])
if i%10 == 0:
print('休息4分钟...')
sleep(240)
print('评论爬取结束...')
if __name__ == '__main__':
# init()
spider()
# getLyric('66842')